
Introduction
For this project we are going to take a overly simplistic approach to predicting sentiment analysis of online reviews: simply count the words associated with positive and negative reviews as well as number of all capitalized words and number of exclamation marks. I suspect that positive reviews contain more exclamation marks while negative reviews tend to have more all capitalized words. In reality, 1 in every 12.8 positive reviews contain an exclamation mark, while only 1 in every 27 negative reviews contain an exclamation mark. This feature could provide good explanatory power so lets include it! Furthermore, 1 in every 3 positive reviews is in all caps, while 2 in every 3 negative reviews are in all caps - so add this as well!
pos_words = ['great','works','love','best',
'good','nice','working','excellent',
'good','fine','sturdy']
neg_words = ["don't","waste","not","worst",
"didn't","bad","difficult","poor",
"doesn't","return","broke"]
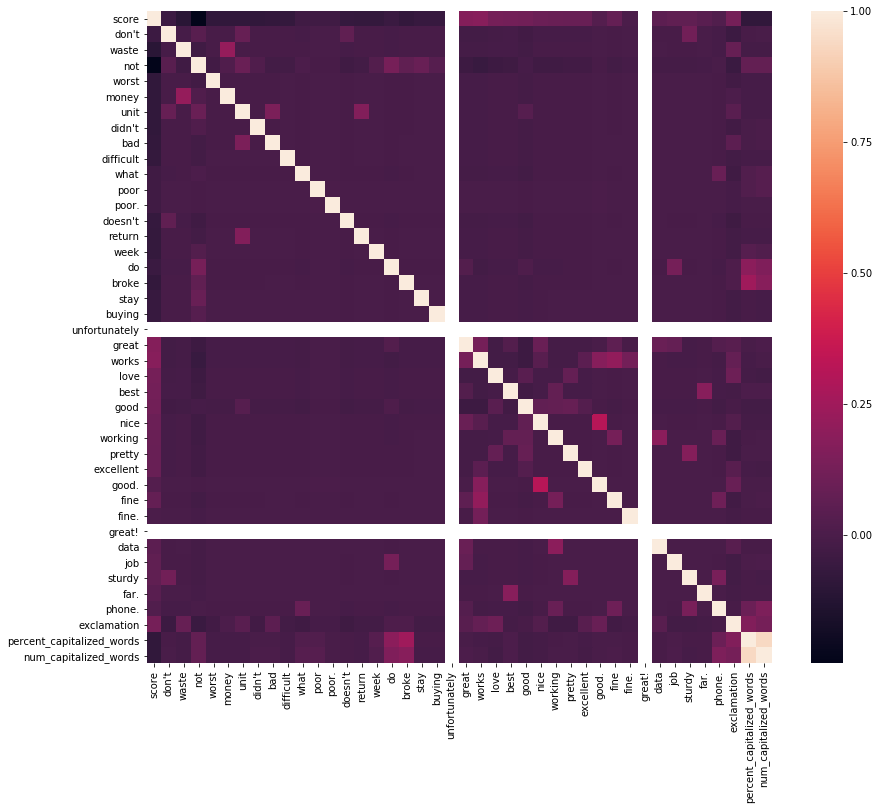 Our input features (positive and negative words) do not appear to be correlated. So now we will simply create a Bernouli Naive Bayes classifier.
Our input features (positive and negative words) do not appear to be correlated. So now we will simply create a Bernouli Naive Bayes classifier.
Data Splits
For this project I will be splitting my data into 70/30 train/test sets. Moreover, I will be using the Yellowbrick package for model visualization.
Model
from yellowbrick.classifier import ClassificationReport
# Instantiate our model and store it in a new variable.
bnb = BernoulliNB()
# Fit our model to the data.
bnb.fit(X_train, y_train)
print('Train score: {:.2f}'.format(bnb.score(X_train, y_train)))
# Instantiate the classification model and visualizer
bayes = BernoulliNB()
visualizer = ClassificationReport(bayes, support=True)
visualizer.fit(X_train, y_train) # Fit the visualizer and the model
visualizer.score(X_test, y_test) # Evaluate the model on the test data
g = visualizer.poof()
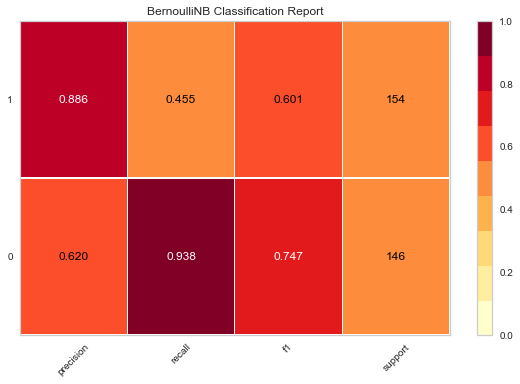
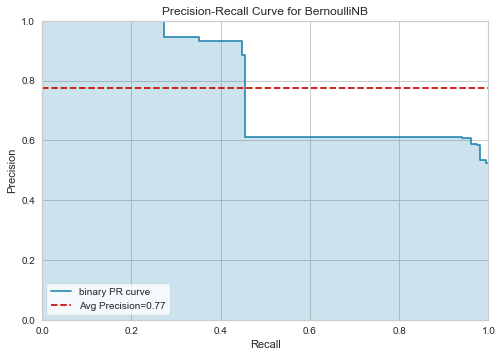
This model was 66% accurate, but the precision-recall curve is not very smooth and thus a hard tradeoff must be made. Is predicting negative reviews more important than predicting positive ones?
IMDB
IMDB reviews do not contain the words difficult and sturdy, and there are a few more words that are correlated (which could be an issue for our model, however none of the correlations appear to be greater than 0.5)
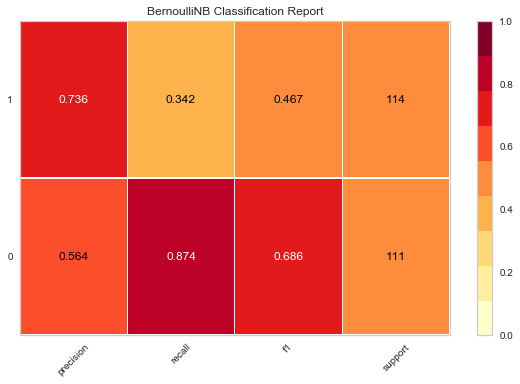
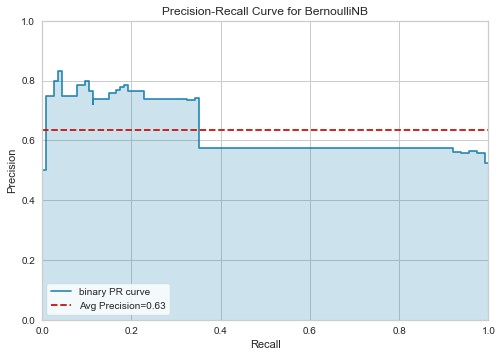
We achieve an accuracy of 60% when using the model trained on Amazon reviews to predict IMDB reviews. Notice that we do not see significant decrease in recall, but this model does suffer when it comes to precision, or how right we are when predicting positive reviews.
Yelp
Yelp reviews do not contain the words: difficult, doesn’t, broke, working or sturdy.
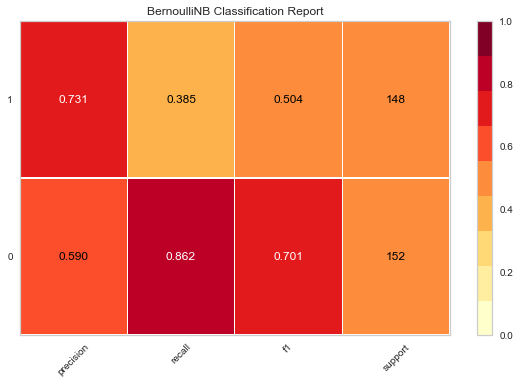
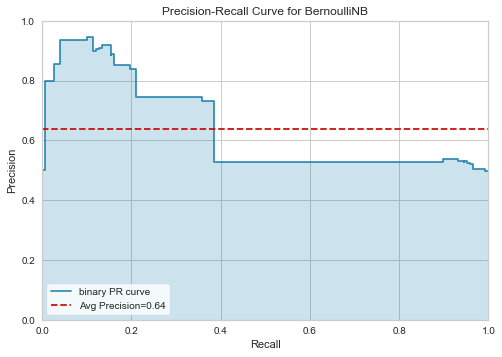
This model is 63% accurate on handling Yelp reviews (trained on Amazon reviews). Here we do see decreased precision and a slight decrease in recall.
Conclusion
We constructed a Naive Bayes classification model by simply using the top frequently used words that were unique to positive and negative reviews, as well as if a review contains an exclamation mark and if the review is all caps (using Amazon reviews). Here were the accuracy rates for each dataset:
- Amazon: 66%
- IMDB: 60%
- Yelp: 63%
As alluded to above, the tradeoff between precision and recall will be critical; if we suspect much larger number of negative reviews we will want to focus on recall, and converting these negative reviews to either neutral (no review) or positive could be much more valuable! More information will be needed in order to make this call.
The source code for this project can be found on GitHub