
“If you want to understand people, especially your customers…then you have to be able to possess a strong capability to analyze text.” - Paul Hoffman, CTO:Space-Time Insight
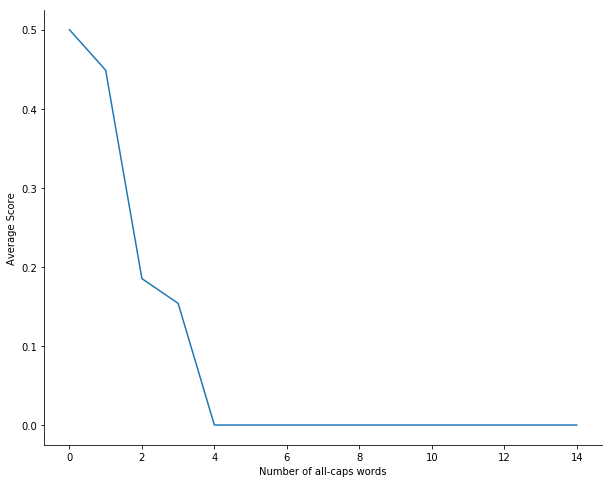
This project builds on previous work, with the additions of part-of-speech (POS) tagging and NLTK/VADER sentiment scores. Furthermore, we include the binary feature of containing at least one all-caps word.
VADER Sentiment Analysis
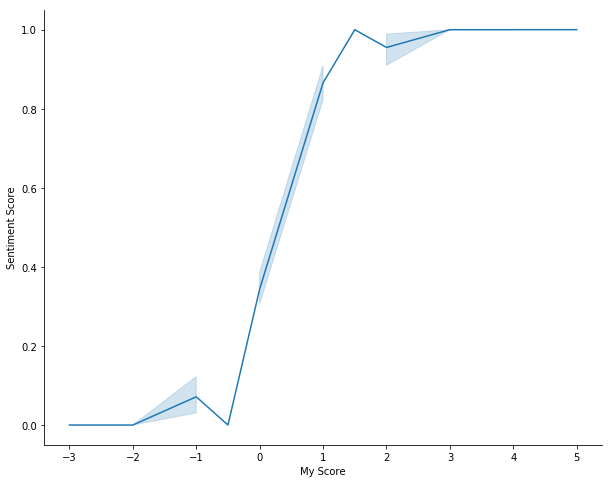
VADER (Valence Aware Dictionary and sEntiment Reasoner) is a lexicon and rule-based sentiment analysis tool that is specifically attuned to sentiments expressed in social media. VADER uses a combination of A sentiment lexicon is a list of lexical features (e.g., words) which are generally labelled according to their semantic orientation as either positive or negative. VADER has a lot of advantages, specifically it does not require any training data as it is constructed from a generalizable, valence-based, human-curated gold standard sentiment lexicon. VADER is also fully open-sourced under the MIT License.
VADER assigns polarity scores to text, one corresponding to positive polarity, neutral, negative and compound.
- The Positive, Negative and Neutral scores represent the proportion of text that falls in these categories.
- The Compound score is a metric that calculates the sum of all the lexicon ratings which have been normalized between -1(most extreme negative) and +1 (most extreme positive).
The VADER algorithm is quite complex, there are a lot of papers discussing it’s various aspects. I applied VADER to all Amazon reviews, here are the results:
| negative | neutral | positive | compound | |
|---|---|---|---|---|
| rating | ||||
| 0 | 0.197 | 0.753 | 0.05 | -0.185 |
| 1 | 0.0128 | 0.632 | 0.355 | 0.46 |
Not surprisingly, there is not much difference in the neutral score the VADER sentiment system assigns our reviews, while there is a significant difference in the positive and compound scores, and a noticeable difference in the negative scores. This appears to be pretty promising for our model.
Model
For this task I will build 5 different models and compare how they perform. Each model will use 5-fold cross validation.
- The first model will be of the same configuration as before: Bernouli Naive Bayes classifier using our top positive/negative words, as well as binary variables if the review cotains an exclamation mark or a word in all caps (minimum length of 2).
- The second model will also include bigrams, or word pairs, that are explictly declared:
['do not', 'no problem', 'the best', 'loved it','the best', 'the greatest','so good','so great', 'not good', 'not bad', 'really great','really bad', 'really good', "very good", 'not impressed','very impressive', 'well made', 'badly made', 'not great', 'too big', 'too small', 'very poor', 'not working','working good', "doesn't work", "didn't work", "doesn't fit", "wouldn't recommend", 'would recommend', 'not nice', 'not working','not easy', 'not happy']We also include the number and percentage of all-caps words.
- For our third model, we will incorporate part-of-speech tagging. The logic behind computing these scores is worthy of it’s own post, but for now the source code can be found here.
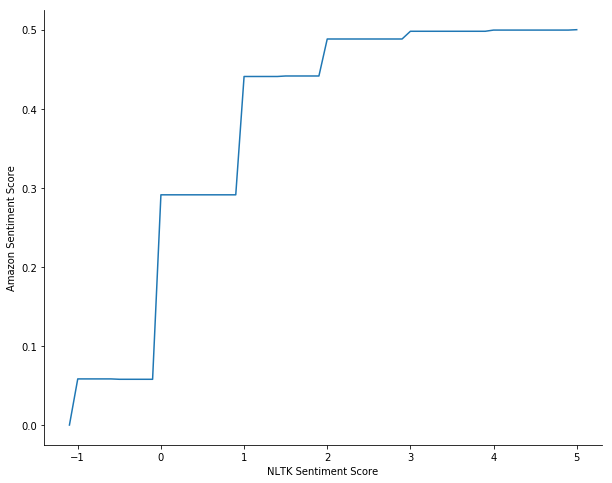
- Now we are going to use VADER.
- Our final model will use both POS tagging and VADER.
Because this is a classification problem, what do we want to optimize? If the majority of positive reviews are not very meaningful, we may care more about specitivity than sensitivity. Therefore, we report all meaningful metrics.
| Accuracy | Sensitivity | Specitivity | |
|---|---|---|---|
| Model | |||
| 1 | 66.9 | 42.0 | 92.6 |
| 2 | 68.5 | 44.4 | 92.8 |
| 3 | 77.4 | 61.8 | 93.0 |
| 4 | 83.3 | 82.0 | 84.6 |
| 5 | 82.9 | 82.0 | 84.6 |
Conclusion
As alluded to above, there will be a tradeoff between sensitivity and specitivity, and the business goals will dictate this decision. With that being said, using VADER achieved fairly high sensitivty and specitivity scores, while model 3 (which used POS-tagging) was very good at predicting bad reviews (93%) but not great at predicting positive reviews (61.8%). In my opinion, positive reviews will increase sales of that product, but if we can identify what is causing negative reviews that could turn negative reviews into positive ones, leading to even more sales.
You can find the full source code here.